Malicious URL Detection with ML
Malicious URL Detection using Machine Learning
Summary
In this article, I’ll share how I tackled the challenge of detecting malicious URLs using a machine learning model that incorporates both lexical and external features.
Before embarking on this project, I had no prior knowledge or experience with machine learning and its various algorithms, nor with some of the necessary Python libraries. I spent the last few days learning from Kaggle and other online resources to fill in these gap.
What is a URL?
Before diving into the project details, let’s take a moment to understand what a URL is.
According to TechTarget, a URL (Uniform Resource Locator) is a unique identifier used to locate a resource on the Internet. It is also referred to as a web address. URLs consist of multiple parts - including a protocol and domain name - that tell a web browser how and where to retrieve a resource.
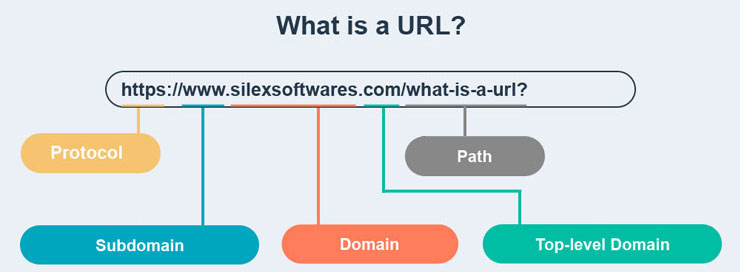
The URL contains the name of the protocol needed to access a resource, as well as a resource name. The first part of a URL identifies what protocol to use as the primary access medium. The second part identifies the IP address or domain name - and possibly subdomain - where the resource is located.
Optionally, after the domain, a URL can also specify:
- a path to a specific page or file within a domain;
- a network port to use to make the connection;
- a specific reference point within a file, such as a named anchor in an HTML file;
- a query or search parameters used – commonly found in URLs for search results.
And a malicous URL?
A malicious URL is a link created with the intent to promote scams, attacks, and frauds. When clicked, malicious URLs can download ransomware, trojans, lead to phishing emails, or cause other forms of cybercrime. These URLs are often disguised and easy to miss, making them a serious threat in the digital world.
To avoid malicious URLs, do not open suspicious links or download files from suspicious emails or websites!
Diagram
In this project we will detect malicious URLs based on some of its features and with the help of machine learning.
Every line of code was developed on my local jupyter notebook. You can install Jupyter by following the instructions here.

Dataset Management Process
Dataset Description
To create our prediction script, we first need a dataset to train our model. This dataset, final_raw_data.csv, consists of 1298000 URLs and it has two columns: the URL itself and a label indicating whether it is benign (“0”) or malicious (“1”).
Layout:
- 49524 benign URLs (source: Alexa Top Websites)
- 1248476 malicious URLs (source: OpenPhish’s Feed from July 05-08 of 2024, and the rest from PhishTank database)
Due to the imbalance in the dataset, we only selected a portion of the URLs to ensure a 50/50 distribution during the next steps.
Data Preprocessing - Stage 1
To “clean” our dataset, we need to remove duplicates and null values, as these could affect our ML model. To achieve this, we used Pandas library:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# import pandas
import pandas as pd
# Open csv dataset
dataset = pd.read_csv('/path/to/dataset.csv')
# Check number of duplicates
dataset.duplicated().sum()
# Drop them
dataset = dataset.drop_duplicates()
# Drop NA values
dataset.dropna()
This process was already applied to our final_raw_data.csv file, so we still retain the 1298000 URLs.
Whois Verification - Stage 2 & 3
After preprocessing our data, we checked which URLs are reachable via whois. This is one of the most important steps because of the features we were able to extract from it: domain registration and expiration date.
Malicious URLs typically have shorter registration and expiration periods. Therefore, if a domain is recent with an expiration date within two years, the probability of it being malicious is high.
Although many phishing/malicious campaigns use newly creates domains, an old domain is not necessarily safe. An attacker can take ownership of an expired domain and use it for malicious activities!
To expedite the project, we divided the data into two datasets: malicious and benign, and performed Whois verification on 10000 URLs from each.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# Import libraries
import pandas as pd
import numpy as np
import whois
import concurrent.futures
import time
# Read the csv file
urls = pd.read_csv('final_raw_data.csv', encoding = "ISO-8859-1")
# 10k sample list
sample_1 = urls['URL'][49524:50899] # contains Openphish's Feed from 05/07
sample_2 = urls['URL'][1289374:1297999] # contains the other feeds URLs and PhishTank data
phish_sample = pd.concat([sample_1, sample_2])
# Whois Function
def performwhois(url):
try:
result = whois.whois(url)
return True #success
except Exception as e:
print(f"WHOIS lookup failed for {url}: {e}")
return False #error
phish_urls = []
counter = 0
for url in phish_sample:
if performwhois(url):
counter = counter + 1
print(counter)
phish_urls.append(url)
In the end, We verified 8412 malicious and 9949 benign URLs. We then merged the results into a single .csv file, ensuring an equal number of benign and malicious URLs — 8400 each.
Features Extraction - Stage 4
Now that we have our “final” dataset ready, we can start to extract features to train our model. In this project, we extracted 16 lexical features and 2 external/whois features:
External/Whois features:
- Registration Date: Older URLs are more likely to be benign.
- Expiration Date: Most threat actors do not keep their domains active for long periods.
Lexical Features:
- Having the IP address in the URL: Attackers might use an IP address (IPv4 or IPv6) to hide the website’s identity.
- Having the port in the URL: Non-standard ports may indicate attempts to avoid detection or host malicious content.
- Number of “.”: Phishing/malware websites might use more than two sub-domains in the URL. Each domain is separated by dot (.). If any URL contains more than three dots, then it increases the probability of being a malicious site.
- Number of “@”: The “@” symbol can obfuscate the true URL.
- Number of “-“: Dashes are often used to mimic legitimate URLs.
- Number of “//”: Multiple “//” might indicate obfuscation or additional redirections.
- Number of “/”: An unusually high number of slashes might indicate deep directory structures, often used in phishing or malicious URLs to hide the true nature of the site.
- Number of special characters (; += _ ? = & [ ]): Special characters are often used in URL encoding, tracking parameters, or to evade detection.
- Number of “www”: Generally, safe websites have one “www” in their URL.
- Number of “.com”: Multiple “.com” instances can indicate redirections, URL cloaking, or phishing attempts.
- Number of protocols: Multiple protocols might indicate attempts to obfuscate the URL or include multiple redirections.
- Number of subdomains: Malicious URLs might use multiple subdomains to appear legitimate or to evade detection.
- HTTP check: Lack of HTTPS is a stronger indicator of malicious intent, although presence alone is not a guarantee of safety.
- URL length: Attackers generally use long URLs to hide the domain name.
- Short URLs: URL shorteners can hide the actual destination URL, which is often used in malicious campaigns.
- Number of digits: Safe URLs generally do not have digits so counting the number of digits in URL is an important feature for detecting malicious URLs.
We extracted these features using our script (availablee here), and saved the results as features.csv to finally use it to train our model.
Exploratory Data Analysis (EDA) - Stage 5
Before diving into our ML model, let’s take a look at each feature and its representation through our dataset. Even though we extracted a lot of important information, if our dataset don’t follow the intended results, our model won’t be accurate when faced with new URLs.
Exploratory Data Analysis (EDA) is performed to understand and gain insights from the data before conducting further analysis or modeling. It helps in identifying patterns, trends, and relationships within the dataset.
To perform this analysis, we used matplotlib and seaborn graphical capabilities:
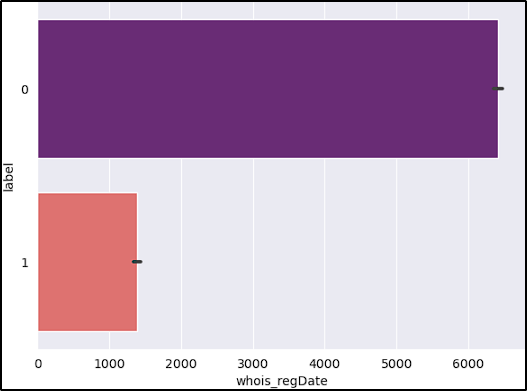
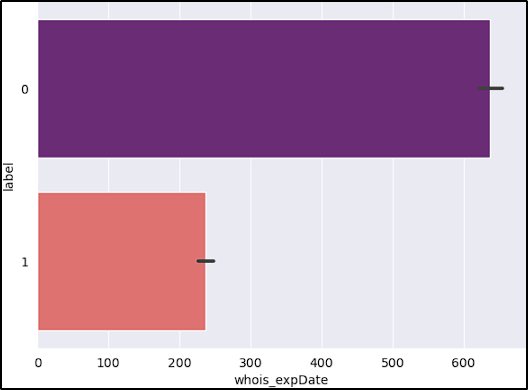
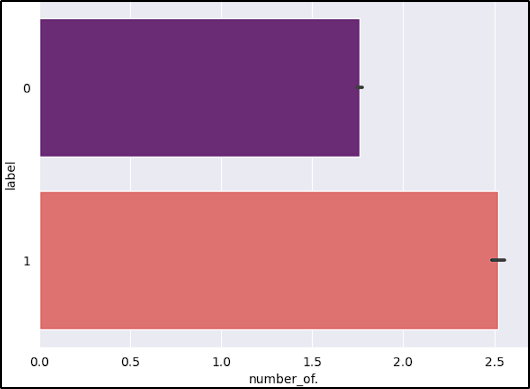
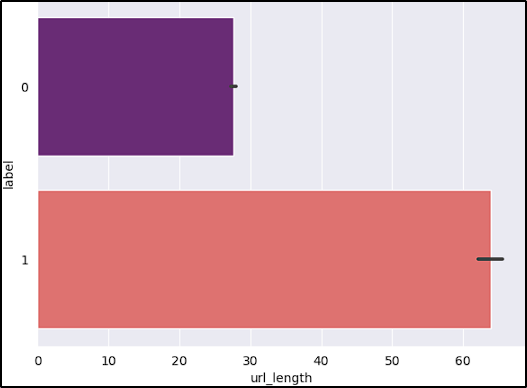
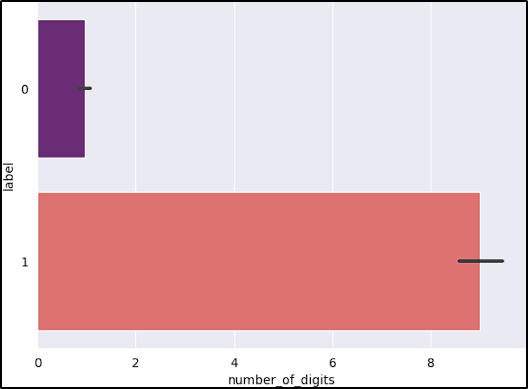
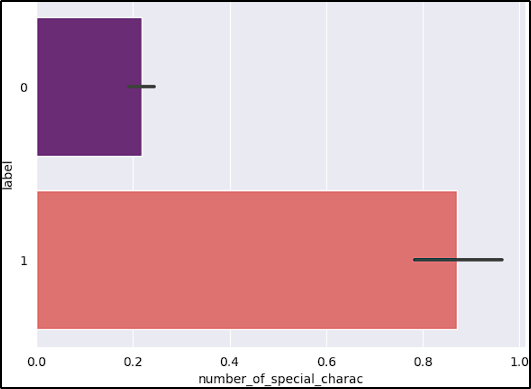
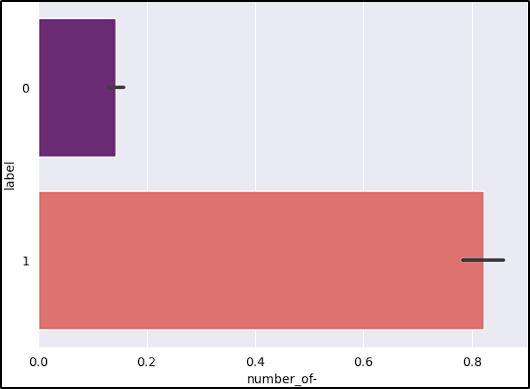
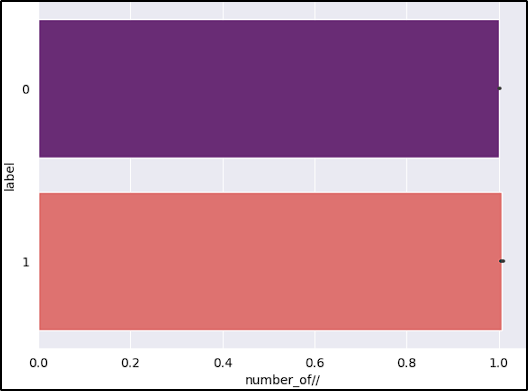
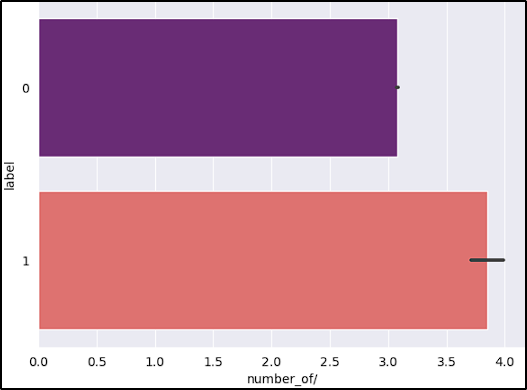
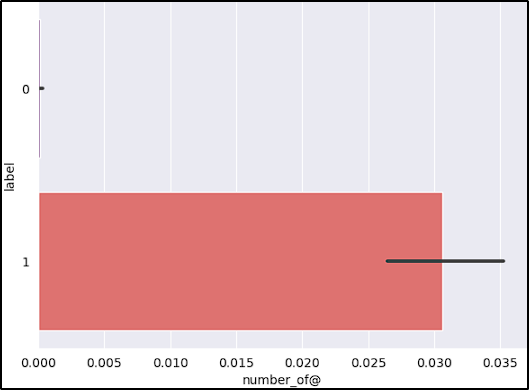

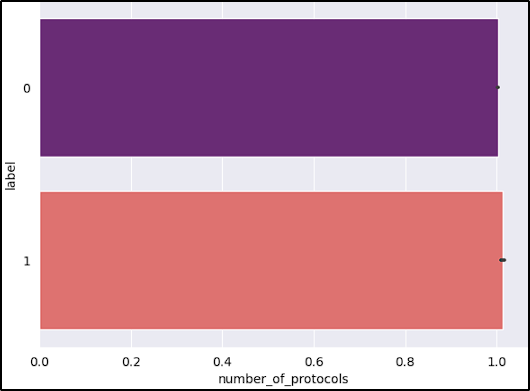
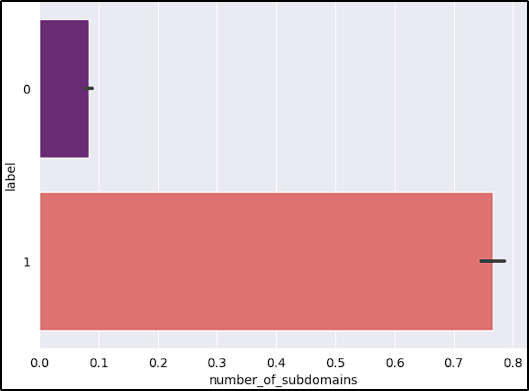
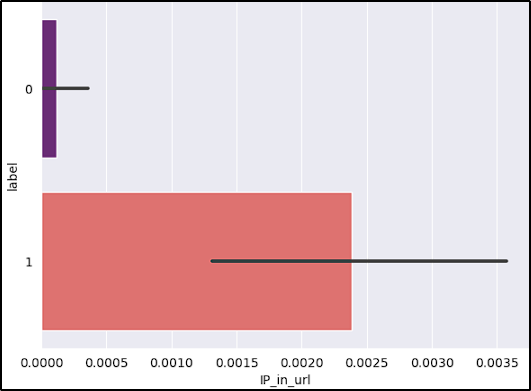
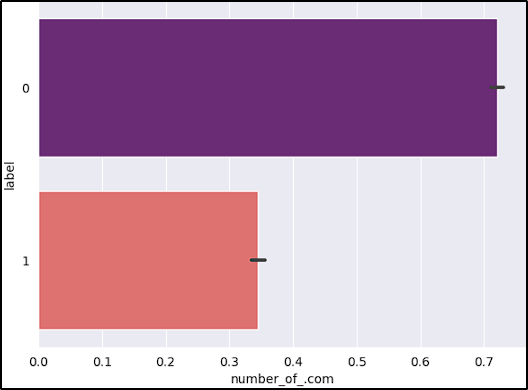
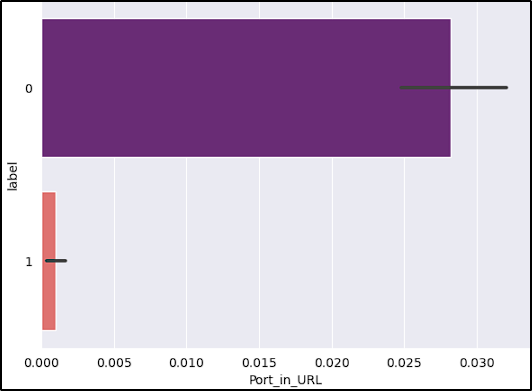
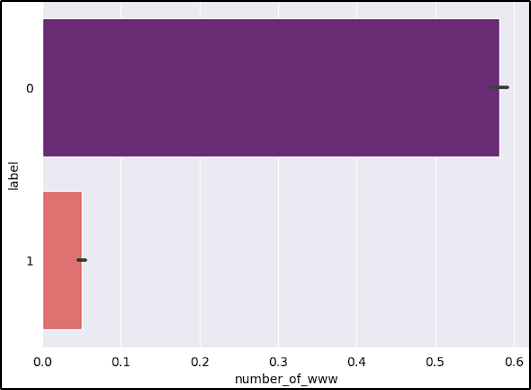
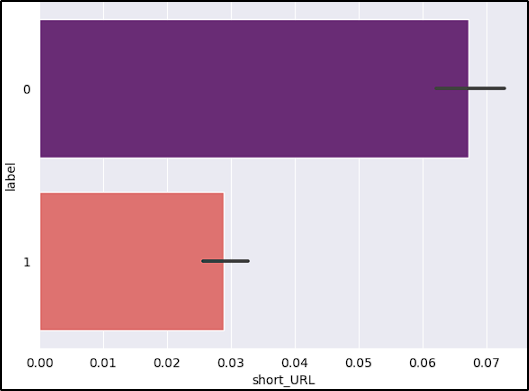
After reviewing the graphs, the features short_URL and Port_in_URL could impact our model negatively due to their distribution across benign and malicious URLs. The number_of_protocols could also be a problem, because the majority of benign URLs don’t start with the protocol (www.example.com).
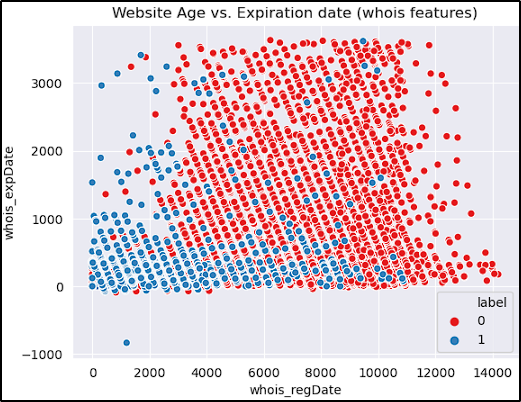
Here we can see what we already said, the majority of benign/legit URLs are older and have higher expiration dates. Additionaly, that one malicious URL with the significant negative expiration date, altought we didn’t drop it, it might be a good practice to do so because of its disparity.
Machine Learning - Stage 6
Now that we have our data ready and we know each columns to drop, it is time to start training our model.
First, we created our X and y variables. X contained the features to train the model, and y contained the label of each URL.
1
2
3
4
5
6
7
8
9
10
11
12
# Import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Read csv
features = pd.read_csv('../Data/features.csv')
label_data = pd.read_csv('../Data/merged_whois_urls.csv')
# X and y values
X = features.iloc[:, [0,1,2,3,4,5,6,7,8,9,10,12,13,14,16]].values # Dropped column 11,15 and 17
y = label_data.iloc[:, [1]].values
Next, we split our dataset into train and test sets. We used 20% of the data (3360 URLs) for testing and the remaining 80% (13440 URLs) for training.
1
2
3
# Training and testing data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
Now, we are ready to train/test our data with different Machine Learning algorithms.
Model Building
We trained our Machine Learning model with the following algorithms: Decision Trees, Support Vector Machine (SVM), Kernel SVM and Random Forest (all code here).
- Decision Tree: A decision tree is a supervised learning algorithm that is used for classification and regression modeling. Regression is a method used for predictive modeling, so these trees are used to either classify data or predict what will come next.
- Support Vector Machine (SVM): The goal of an SVM is to find the hyperplane that best separates the different classes in the feature space. In linear SVM, a linear decision boundary is used to separate classes. The algorithm aims to find the hyperplane with the maximum margin, which is the distance between the hyperplane and the nearest data points from each class, known as support vectors.
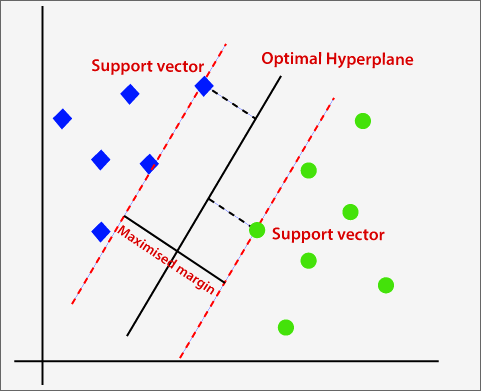
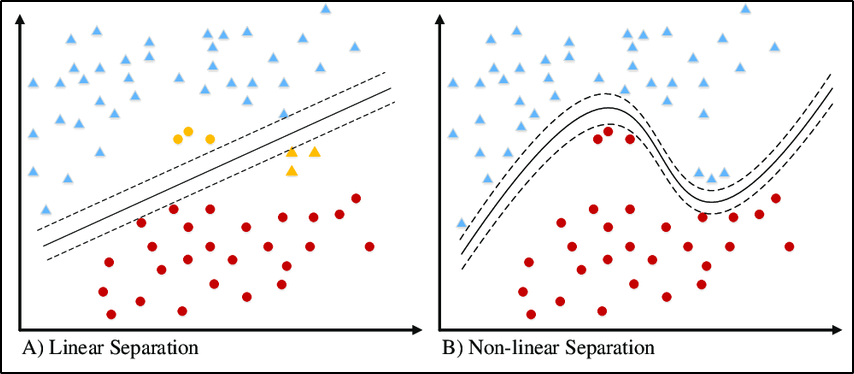
- Kernel SVM: A Kernel SVM uses a kernel function to transform the data into a higher-dimensional space where it can be linearly separated. This allows SVMs to create non-linear decision boundaries.
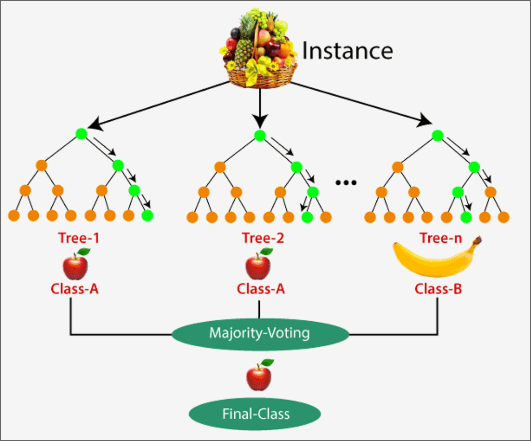
- Random Forest: It works by creating a number of Decision Trees during the training phase. Each tree is constructed using a random subset of the data set to measure a random subset of features in each partition. This randomness introduces variability among individual trees, reducing the risk of overfitting and improving overall prediction performance. In prediction, the algorithm aggregates the results of all trees, either by voting (for classification tasks) or by averaging (for regression tasks).
Model Evaluation and Comparison
The table and images below show the results achieved by each model (accuracy and confusion matrix):
| Algorithm | Accuracy (%) |
|---|---|
| Decision Tree | 97.53 |
| Support Vector Machine (SVM) | 95.48 |
| Kernel SVM | 97.29 |
| Random Forest | 98.45 |
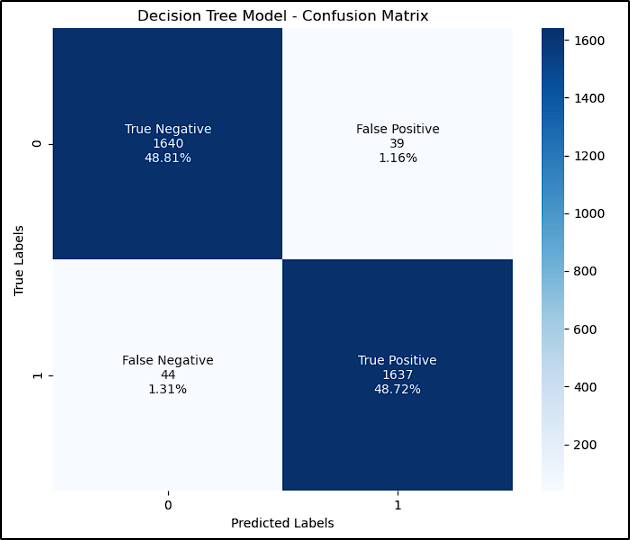
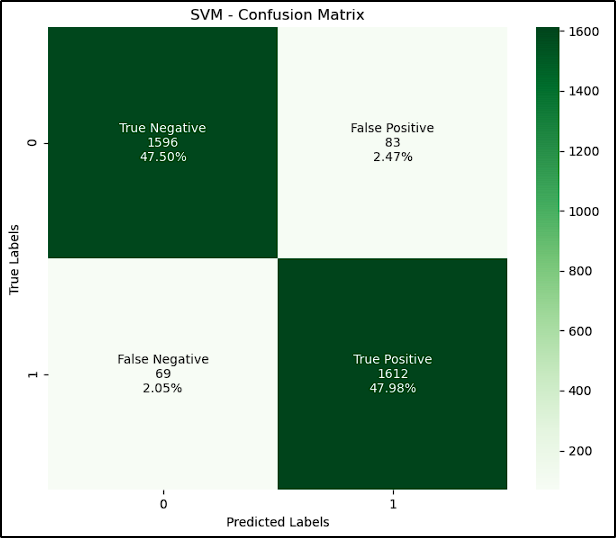
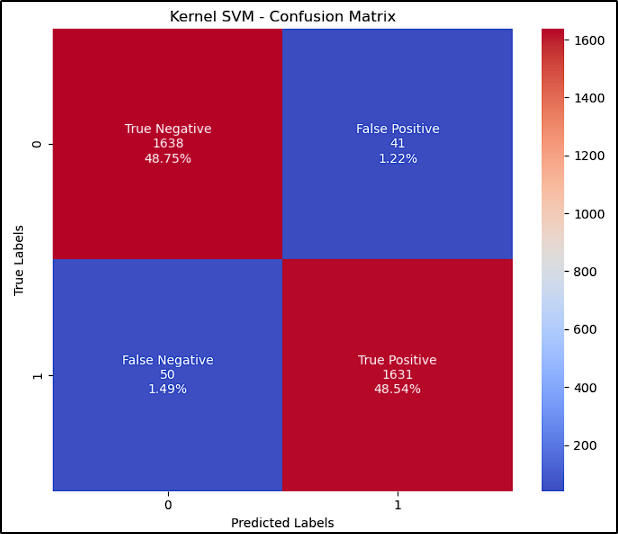
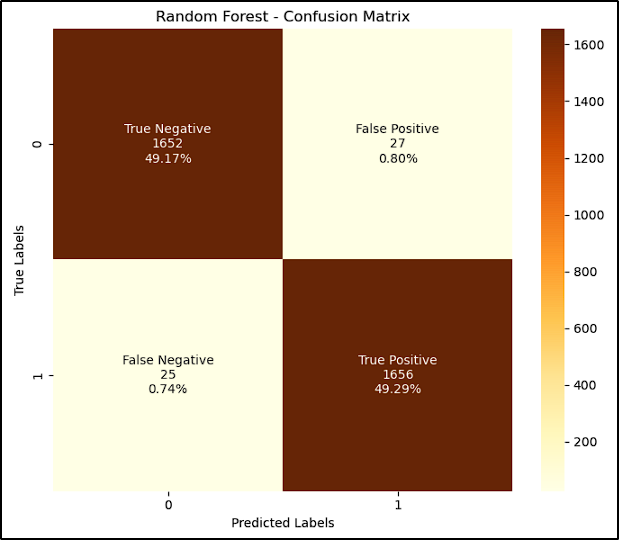
As we can see, all models achieved above 95% score, and the Random Forest algorithm has the best perfomance with 98,45% accuracy. With that, we selected it to our next step, where we’ll test it against new URLs in the Deployment Process.
Deployment Process
Real-Time Prediction using Flask - Stage 7 & 8
With our best model selected, we need to create a script to handle new URLs, extract their features, and use our model to make predictions. Here is the full code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
import re
import pandas as pd
import joblib
import whois
import tldextract
from datetime import datetime
import pytz
from flask import Flask, request, jsonify, render_template
from urllib.parse import urlparse
# Extract Features from a URL
def extract_features(url):
features = {
'whois_regDate': get_whois_reg_date(url),
'whois_expDate': get_whois_exp_date(url),
'number_of.': url.count('.'),
'url_length': len(url),
'number_of_digits': sum(c.isdigit() for c in url),
'number_of_special_charac': get_special_char_count(url),
'number_of-': url.count('-'),
'number_of//': url.count('//'),
'number_of/': url.count('/'),
'number_of@': url.count('@'),
'number_of_.com': url.count('.com'),
'number_of_www': url.count('www'),
'number_of_subdomains': get_subdomain_count(url),
'IP_in_URL': having_ip_address(url),
'HTTP_check': get_protocol(url)
}
return pd.DataFrame([features])
# FEATURE FUNCTIONS
# Extracting whois/external features from URL
# Website age in days using URL created_date
def get_whois_reg_date(url):
try:
whois_result = whois.whois(url)
except Exception:
return -1
created_date = whois_result.creation_date
if created_date:
if isinstance(created_date, list):
created_date = created_date[0]
if isinstance(created_date, str):
try:
created_date = datetime.datetime.strptime(created_date, "%Y-%m-%d")
except ValueError:
try:
created_date = datetime.datetime.strptime(created_date, "%Y-%m-%d %H:%M:%S")
except ValueError:
return -1
if isinstance(created_date, datetime):
today_date = datetime.now()
days = (today_date - created_date).days
return days
else:
return -1
else:
return -1
# Website expiry date in days using URL expiration_date
def get_whois_exp_date(url):
try:
whois_result = whois.whois(url)
except Exception:
return -1
expiration_date = whois_result.expiration_date
if expiration_date:
if isinstance(expiration_date, list):
expiration_date = expiration_date[0]
if isinstance(expiration_date, str):
try:
expiration_date = datetime.strptime(expiration_date, "%Y-%m-%d")
except ValueError:
try:
expiration_date = datetime.strptime(expiration_date, "%Y-%m-%d %H:%M:%S")
except ValueError:
return -1
if expiration_date.tzinfo is None:
expiration_date = expiration_date.replace(tzinfo=pytz.UTC)
today_date = datetime.now(pytz.UTC)
days = (expiration_date - today_date).days
return days
return -1
# Extracting lexical features from URLs
# Number of special characters = ';', '+=', '_', '?', '=', '&', '[', ']'
def get_special_char_count(url):
count = 0
special_characters = [';','+=','_','?','=','&','[',']']
for each_letter in url:
if each_letter in special_characters:
count = count + 1
return count
# HTTP check
def get_protocol(url):
protocol = urlparse(url)
if(protocol.scheme == 'http'):
return 1
else:
return 0
# Number of subdomains (excluding "www")
def get_subdomain_count(url):
# Extract the parts of the domain
extracted = tldextract.extract(url)
# Strip 'www' from the subdomain part if present
subdomain = extracted.subdomain.lstrip('www.')
# Count the subdomains
if subdomain:
subdomain_count = len(subdomain.split('.'))
else:
subdomain_count = 0
return subdomain_count
# IPv4/IPv6 in URL check
def having_ip_address(url):
# Regular expression for matching IPv4 addresses
ipv4_pattern = r'\b(?:\d{1,3}\.){3}\d{1,3}\b'
# Regular expression for matching IPv6 addresses
ipv6_pattern = r'\b(?:[A-Fa-f0-9]{1,4}:){7}[A-Fa-f0-9]{1,4}\b|\b(?:[A-Fa-f0-9]{1,4}:){1,7}:\b|\b::(?:[A-Fa-f0-9]{1,4}:){1,7}[A-Fa-f0-9]{1,4}\b'
# Combine both patterns
combined_pattern = f'({ipv4_pattern})|({ipv6_pattern})'
# Search for either pattern in the URL
return int(bool(re.search(combined_pattern, url)))
# Load the Model
loaded_model = joblib.load('final_model.pkl')
# Flask Service
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
url = request.json['url']
url_features = extract_features(url)
prediction = loaded_model.predict(url_features)
return jsonify({'url': url, 'prediction': 'Suspicious' if prediction[0] else 'Safe'})
if __name__ == '__main__':
app.run(debug=True)
We will use Flask as the interface to interact with the ML model, predicting whether a given URL is suspicious or safe.
Testing - Stage 9
To start testing and verify if our model works, save the script and start Flask with the following command:
1
python3 predict_urls.py
Now, to test a URL with our model, send a POST request to http://127.0.0.1:5000/predict with a JSON payload containing the URL we want to predict, using curl.
1
curl -X POST http://127.0.0.1:5000/predict -H "Content-Type: application/json" -d '{"url":"http://example.com"}'
Let’s test with the first 5 URLs from Openphish’s feed of today (11/07/2024):
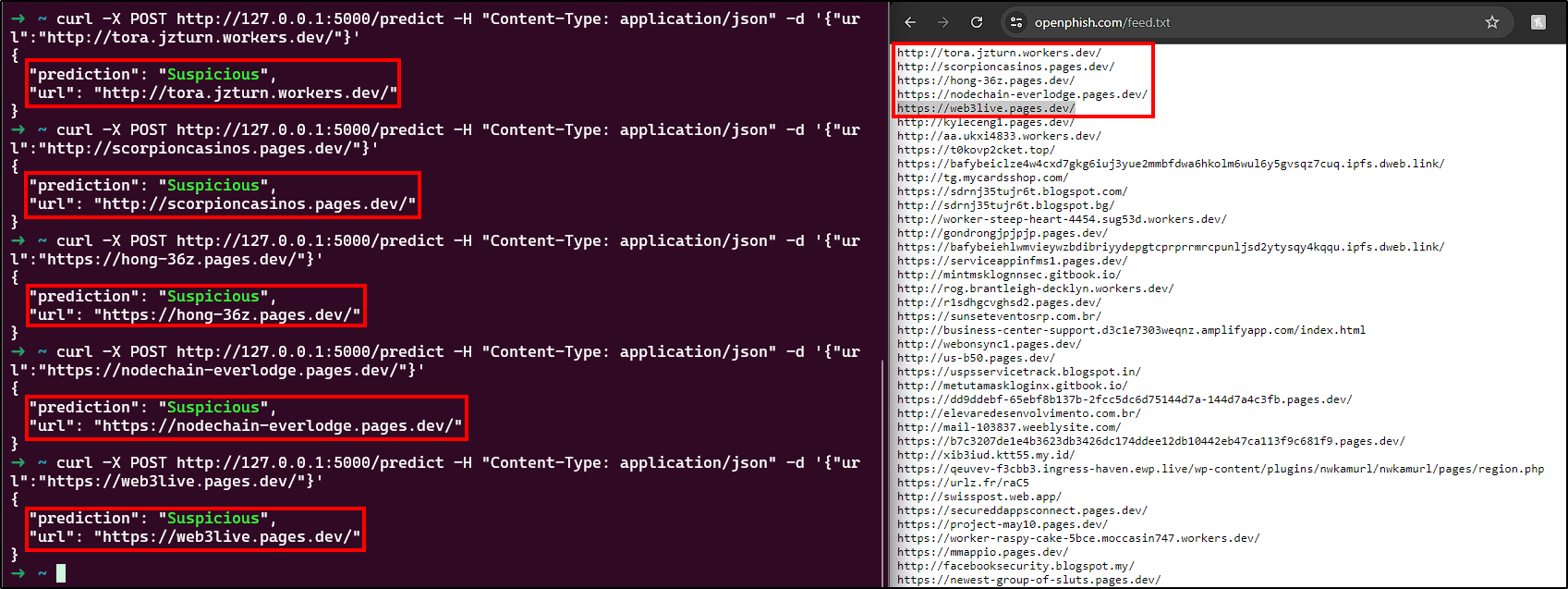
Nice, and against 5 legitimate websites that I used today:
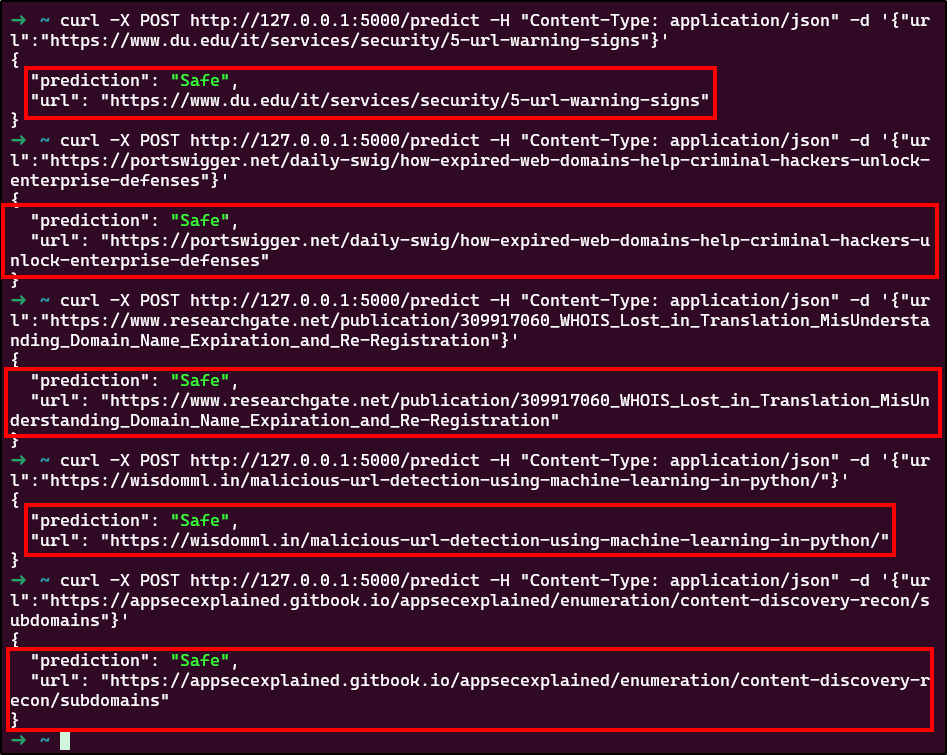
Amazing, our model seems to work very well. But is it really?
Future Work and Improvements
Let’s check the importance of each feature for our model’s prediction process:
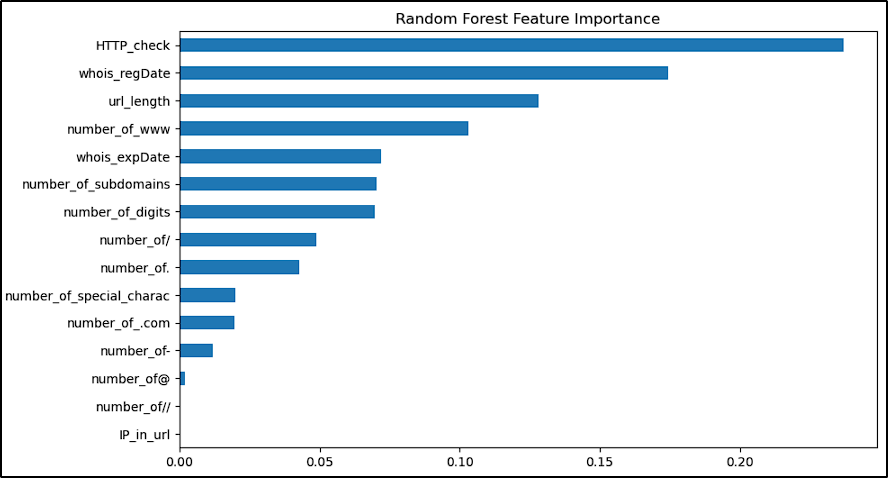
As we can see, HTTP_check, url_length, number_of_www and the whois features have a significant impact in our model’s decision. Although these are important features for verifying the credibility of a URL, they might not be enough.
For example, if we run this blog URL against our prediction model, it is flagged as “Suspicious”. This might be due to its recent registration, low expiration date, no “www”, etc.

A couple of points to consider to prevent these false positives in the future:
- Small dataset: 16800 urls is a small dataset, which could lead to an underfit model;
- Not enough features extracted: We could extract content (Href, Link, Media, Form, CSS, Favicon) and nslookup features next time.
Final Thoughts
What a ride, from knowing nothing about ML to building a model for a task like malicious URL prediction. This project was an amazing opportunity to develop my research capabilities and Python coding skills (even though ChatGPT helped a lot 😁). However, the job isn’t done, and I intend to make some adjustments to the model to enhance its efficiency. Who knows, maybe I’ll start looking into Neural Networks next!